[SLD] SURS - SI-Stat, prenos podatkov
Contents
“Ampak vendar je vsak delavec vreden svojega plačila, to sem v cerkvi slišal.”
Martin K., slovenski legendarni trgovec z orožjem

Na spletni strani statističnega urada RS je veliko podatkov v neobičajnem formatu PC-Axis. Program za ogled in kreiranje podatkov se nahaja na http://www.eustat.eus/prodserv/downl_i.html. Namesto namestitve programa se lahko podatki enostavno pretvorijo v R data.frame s knjižnico pxR. Po potrebi je naslednji korak pretvorba v excel ali kaj podobnega. Glavni problem pri pretvorbah so seveda kot običajno šumniki.
## -- DON'T RUN - eval=FALSE prototype only, no files behind.
#Original pc-Axis datoteka aka px je v ANSI kodiranju. Seveda na oknih popolna zmeda s sumniki.
#najprej nalozim datoteko v originalnem formatiranju - na sreco je vecina datotek majhnih - all in memory
px <- readLines(con = file("0701031S.px"), encoding = "ANSI_X3.4-1986", skipNul = TRUE)
#zapises v LATIN1 in se resis sumnikov in podobnega
cat(px, file = file("temp.px", "w", encoding="LATIN1"), sep = "\n")
#sedaj pa lahko uporabis paket pxR. Problem v paketu dela funcija a <- scan(filename, what = "character", sep = "\n", quiet = TRUE, fileEncoding = encoding)
#paket je githubu in ce se komu ljubi: fork in popravek v tej funciji
library(pxR)
pxo <- read.px("temp.px")
pxd <- as.data.frame(pxo)
#Sedaj pa izvozis nice tidy data v excel, ce zelis.
library(writexl)
writexl::write_xlsx(pxd, path = "tempPX.xlsx")
#pocistim
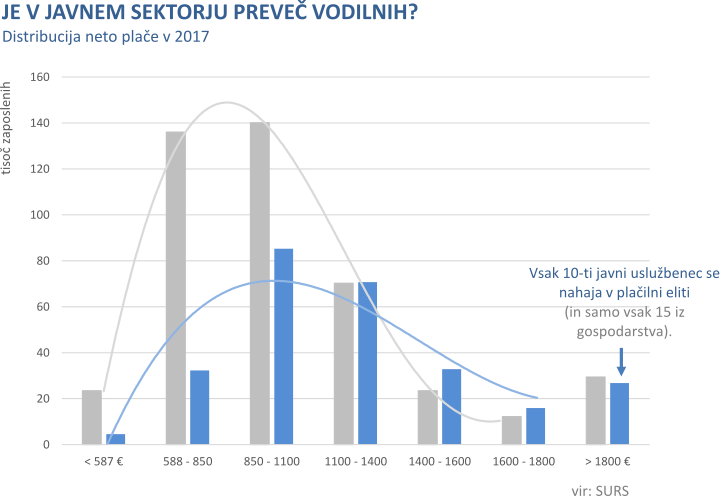
rm(list=c("pxd","pxo", "px"))Če smo že pri slovenski statistiki ne morem mimo podatkov o vedno premalo denarja za plače v javnem sektorju (podatki za leto 2017).
Author SlanaD
LastMod 2019-02-24